![]()
DispatchPolicy
Pre-1.0. Published on RubyGems but the API, schema, and defaults can still shift between minor versions. See
CHANGELOG.mdbefore upgrading.PostgreSQL only. Staging, admission, and adaptive stats lean on
jsonb, partial indexes,FOR UPDATE SKIP LOCKED,ON CONFLICT, and the adapter sharingActiveRecord::Base.connectionso the admit + adapter INSERT can join one transaction. Tested against good_job and solid_queue.
Per-partition admission control for ActiveJob. Stages perform_later
into a dedicated table, runs a tick loop that admits jobs through
declared gates (throttle, concurrency, adaptive_concurrency),
then forwards survivors to the real adapter. The admission and the
adapter INSERT happen inside one Postgres transaction, so a worker
crash mid-tick can't lose a job.
Use it when you need:
- Per-tenant / per-endpoint throttle — token bucket per partition, refreshed lazily on read.
- Per-partition concurrency — fixed cap on in-flight jobs with a release hook on completion and a heartbeat-based reaper for crashes.
- Adaptive concurrency — a cap that shrinks under queue pressure and grows back when workers keep up, no manual tuning per tenant.
- In-tick fairness — within a single tick, partitions are reordered by recent activity (EWMA) and an optional global cap is shared fairly across them. So one tenant's burst can't starve the others.
- Sharding — split a policy across N queues so independent tick workers admit in parallel.
Demo
The demo lives in test/dummy/ — a tiny Rails app inside this repo.
Run it locally to play with every gate and the admin UI:
bin/dummy setup good_job # creates the DB and migrates
DUMMY_ADAPTER=good_job bundle exec foreman startThen open:
-
http://localhost:3000/— playground with one card per job and a storm form that exercises the adaptive cap and fairness reorder across many tenants. -
http://localhost:3000/dispatch_policy— admin UI: live throughput, partition state, denial reasons, capacity hints.
The dummy ships ten purpose-built jobs covering throttle, concurrency,
mixed gates, scheduling, retries, stress tests, sharding, fairness, and
adaptive concurrency. See test/dummy/app/jobs/.
Screenshots
The admin UI lives at /dispatch_policy once the engine is mounted.
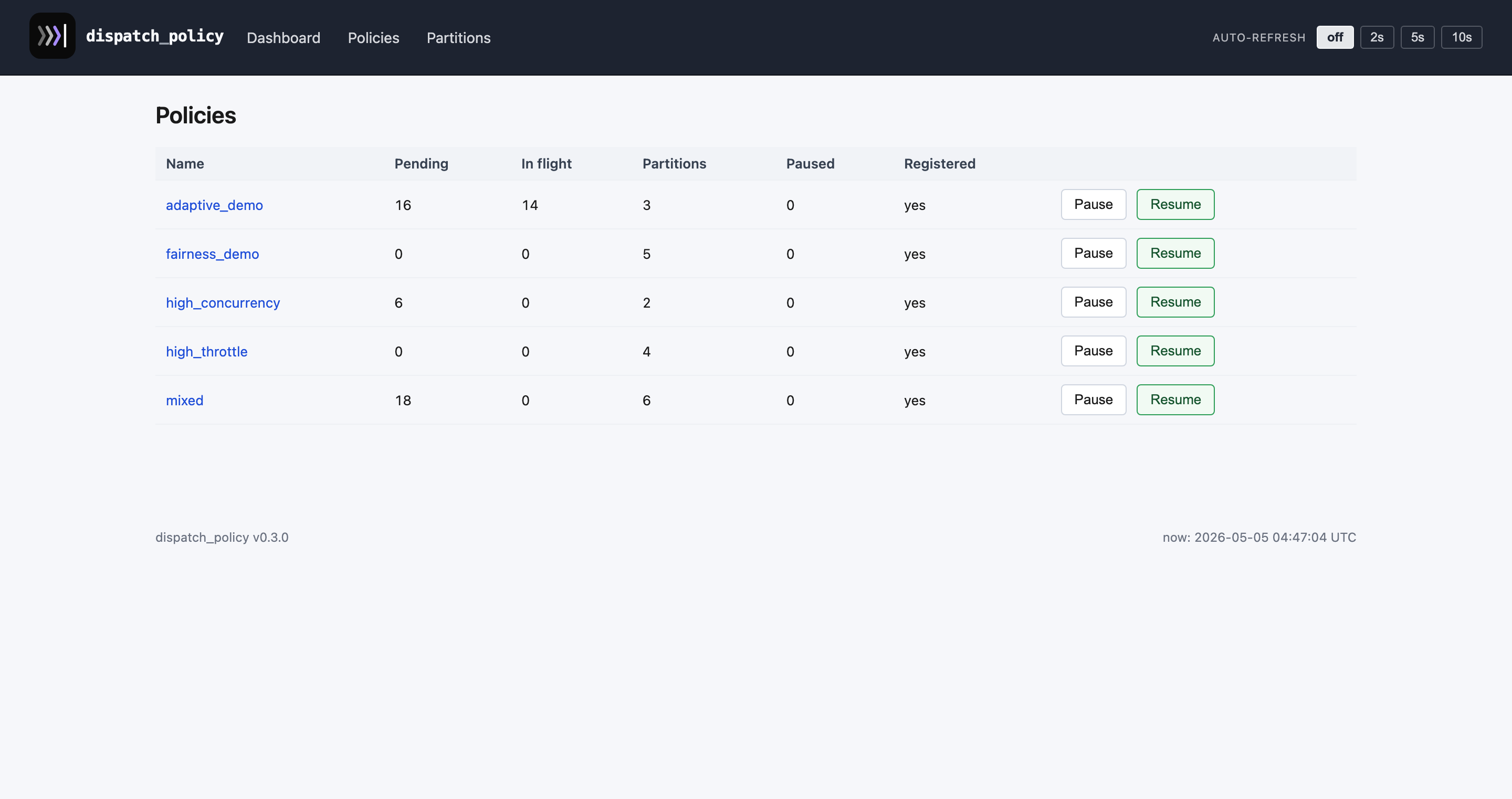
Live throughput, capacity hints, denial reasons, and per-partition
sparklines:
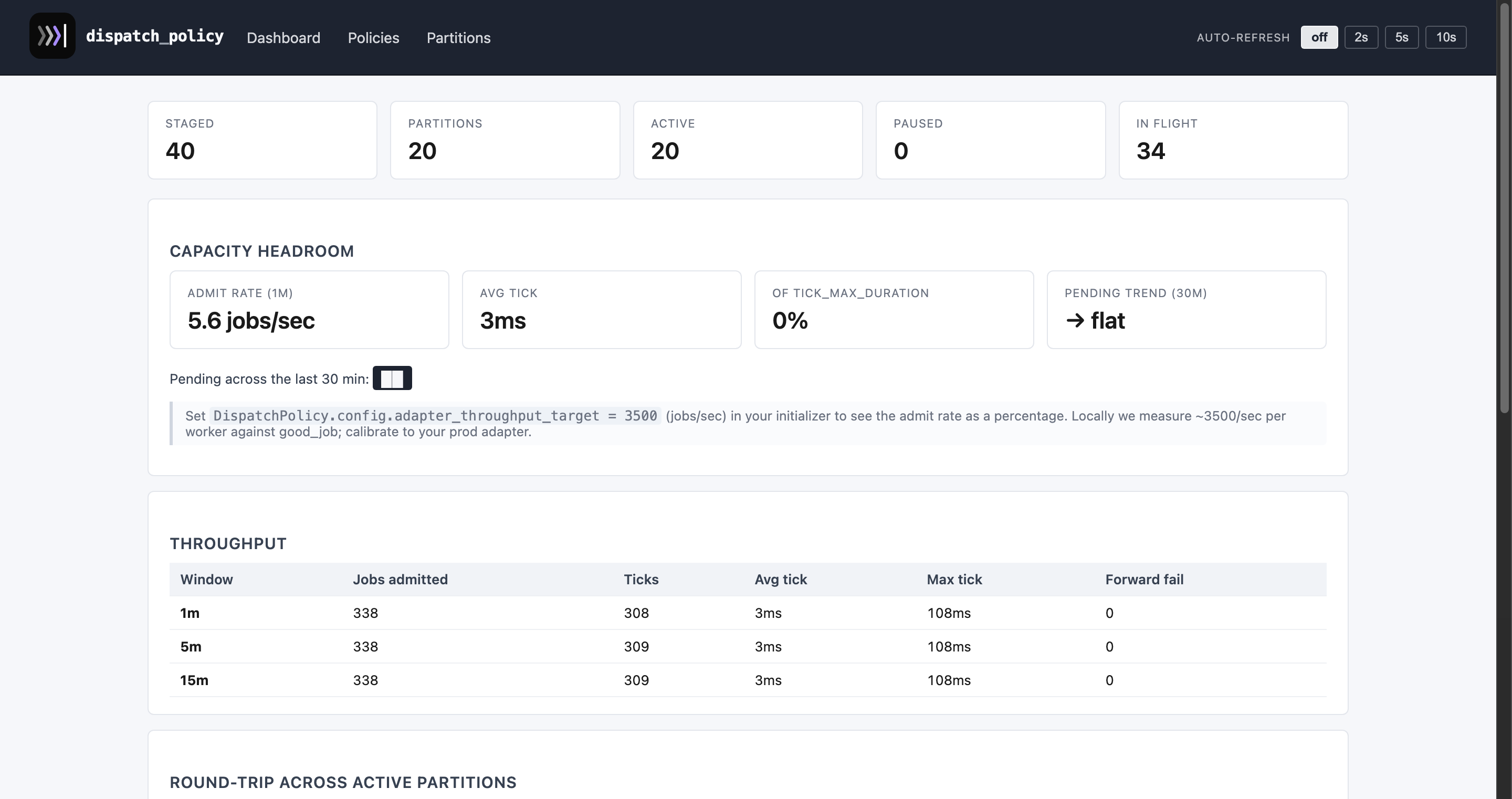
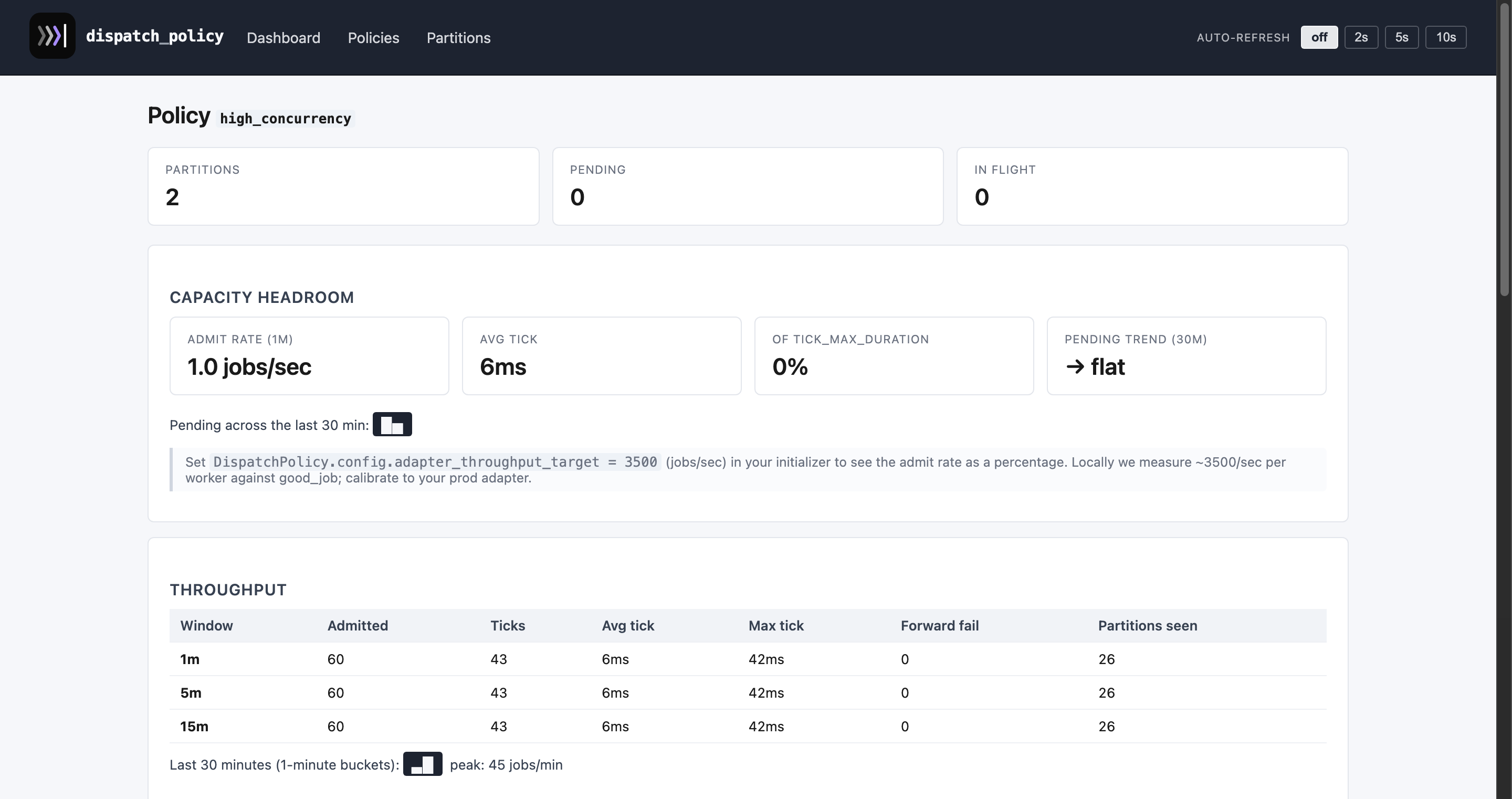
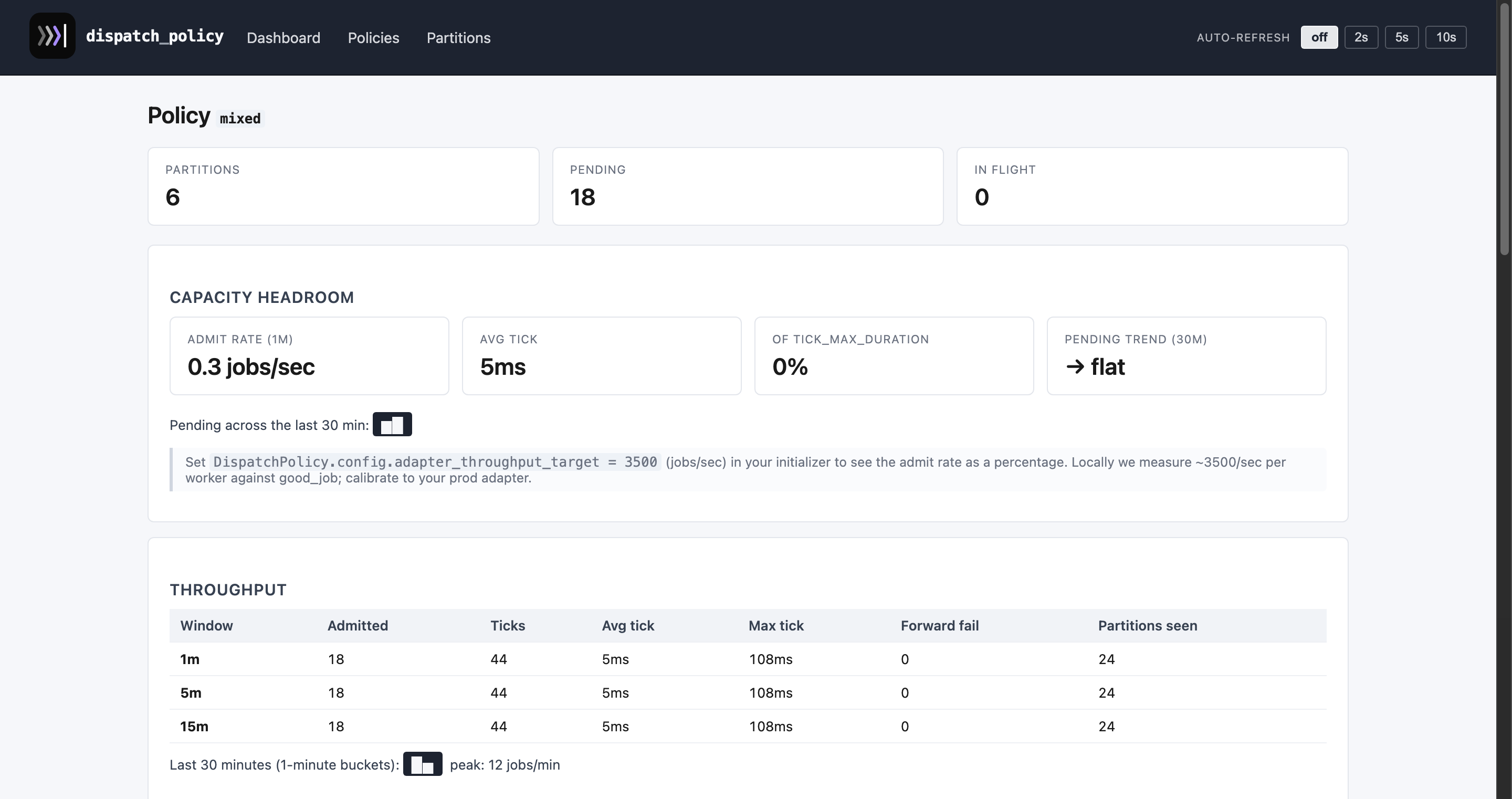
A policy detail page — totals, EWMA queue-lag chart, throughput window, and a searchable list of all partitions:
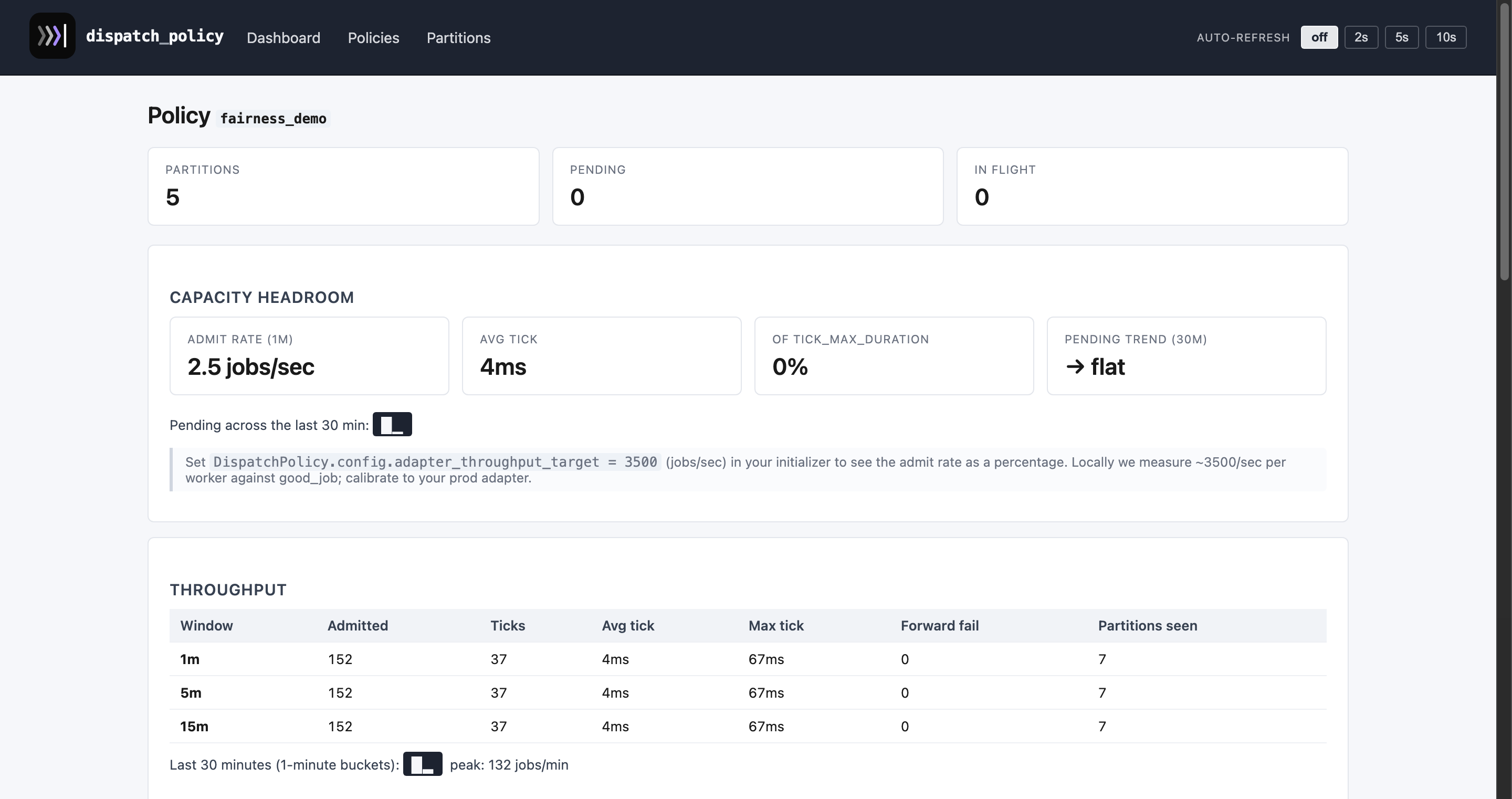
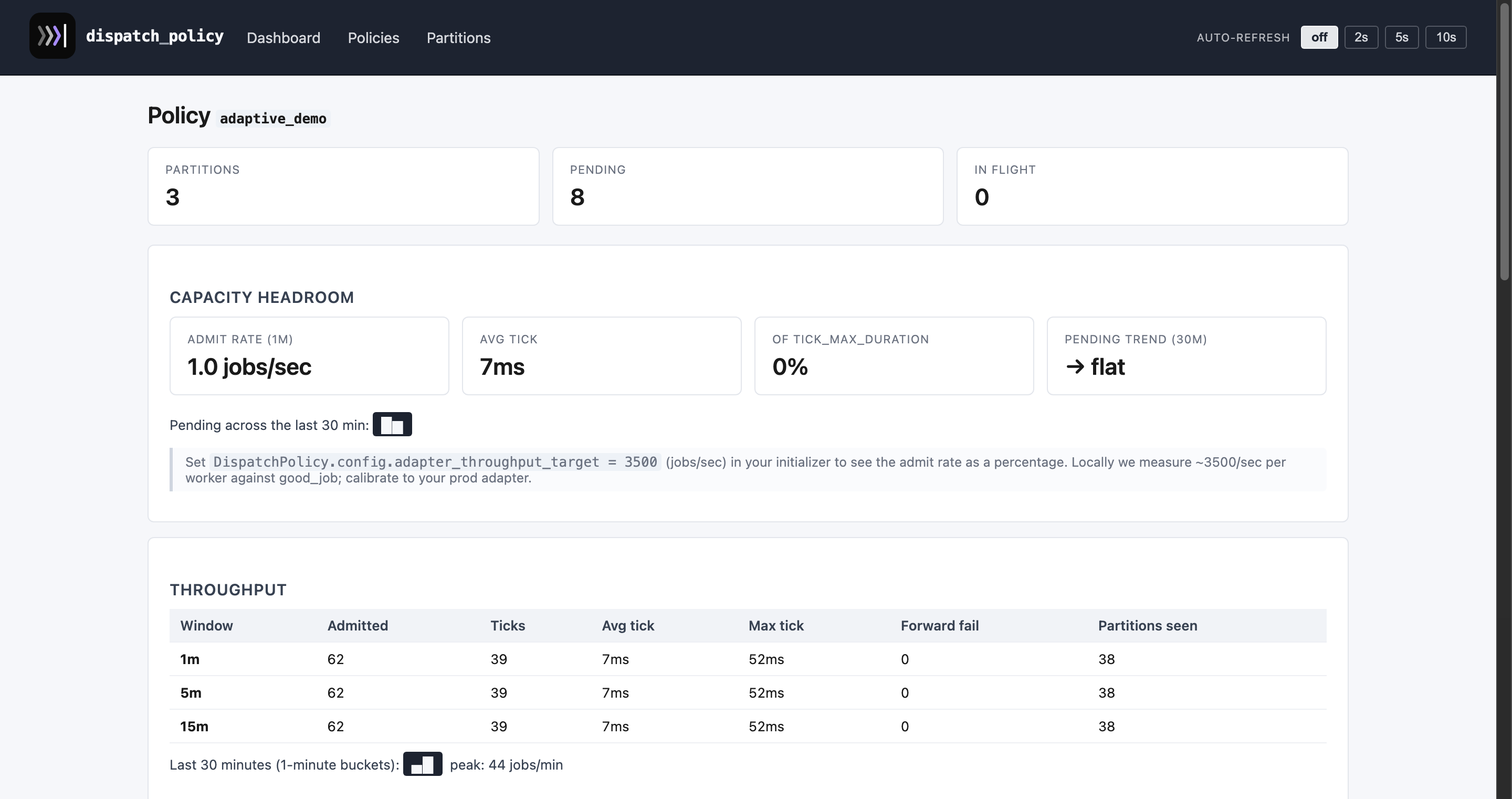
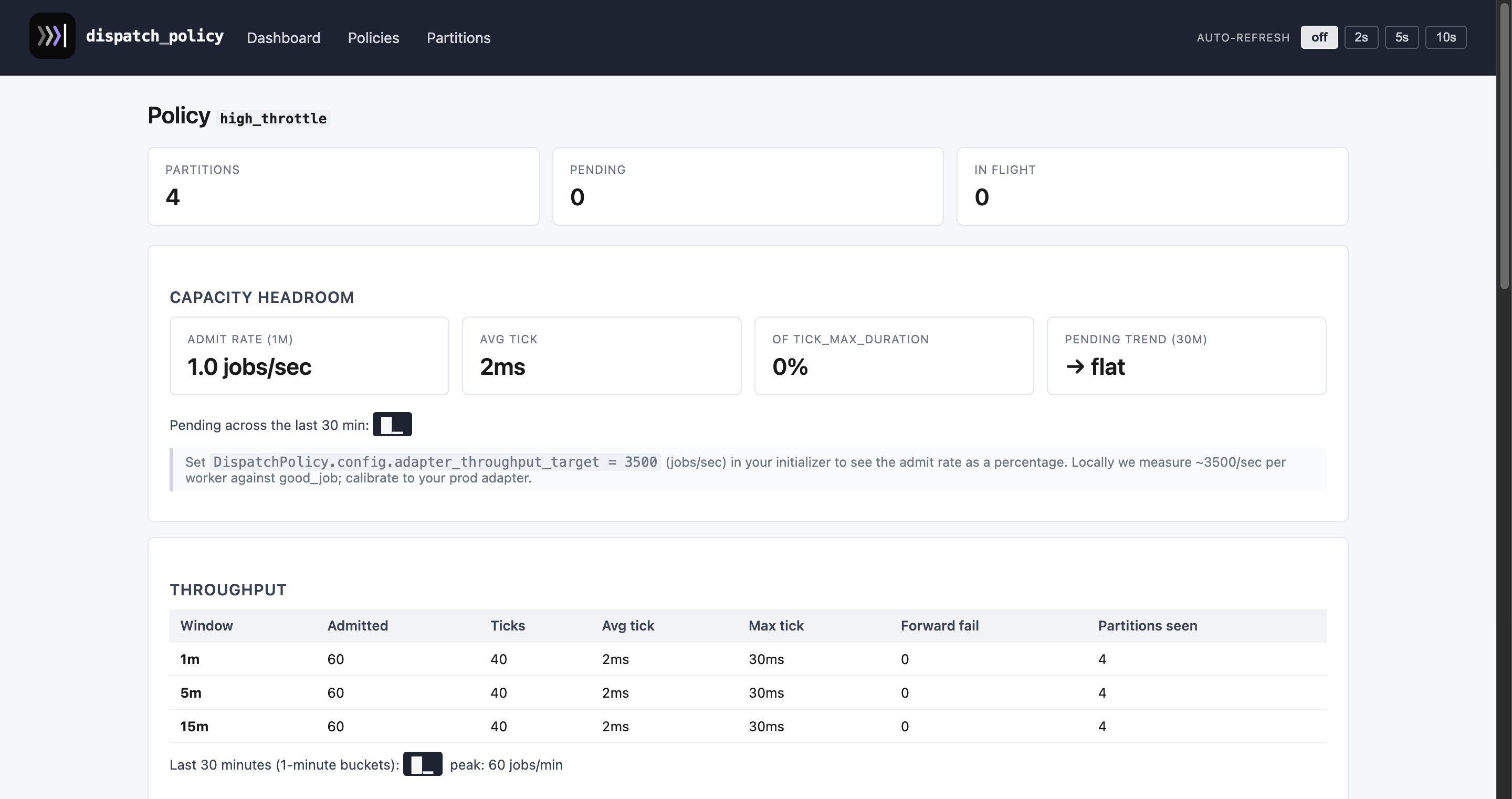
Other per-policy pages: adaptive_demo · high_throttle · high_concurrency · mixed · policies index · partitions index.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Regenerate everything against the dummy app with:
bin/screenshotsThe script seeds realistic state (ticks admit some, GoodJob drains
inline, then a few fresh jobs are left pending) and drives Capybara
with headless Chrome through the admin pages. Stop bin/dummy good_job (or any running tick loop) first so the seeding isn't
racing a live worker — Selenium Manager auto-downloads chromedriver,
you only need Chrome installed locally.
Install
Add to your Gemfile:
gem "dispatch_policy", "~> 0.3"Generate the install bundle (migration + initializer + tick loop job):
bin/rails generate dispatch_policy:install
bin/rails db:migrateMount the admin UI (optional but recommended):
mount DispatchPolicy::Engine, at: "/dispatch_policy"Then schedule the tick loop. The generator wrote a
DispatchTickLoopJob in app/jobs/; kick it off once and it
re-enqueues itself:
DispatchTickLoopJob.perform_laterFlow
ActiveJob#perform_later
→ JobExtension.around_enqueue_for
→ Repository.stage! (INSERT staged + UPSERT partition; ctx refreshed)
(tick loop, periodically)
→ claim_partitions (FOR UPDATE SKIP LOCKED, ordered by last_checked_at)
→ reorder by decayed_admits ASC (in-tick fairness)
→ for each: pipeline.call(ctx, partition, fair_share)
→ gates evaluate; admit_count = min(allowed)
→ ONE TX: claim_staged_jobs! + insert_inflight! + Forwarder.dispatch
(the adapter INSERT shares the TX; rollback if anything raises)
→ bulk-flush deny-state in one UPDATE ... FROM (VALUES ...)
(worker runs perform)
→ InflightTracker.track (around_perform)
→ INSERT inflight_jobs ON CONFLICT DO NOTHING
→ spawn heartbeat thread
→ block.call
→ record_observation on adaptive gates (queue_lag → AIMD update)
→ DELETE inflight_jobs
Declaring a policy
class FetchEndpointJob < ApplicationJob
dispatch_policy_inflight_tracking # only required if a concurrency gate is used
dispatch_policy :endpoints do
context ->(args) {
event = args.first
{
endpoint_id: event.endpoint_id,
rate_limit: event.endpoint.rate_limit,
max_per_account: event.account.dispatch_concurrency
}
}
# Required: every gate in the policy enforces against this scope.
partition_by ->(ctx) { ctx[:endpoint_id] }
gate :throttle,
rate: ->(ctx) { ctx[:rate_limit] },
per: 1.minute
gate :concurrency,
max: ->(ctx) { ctx[:max_per_account] || 5 }
retry_strategy :restage # default; alternative: :bypass
end
def perform(event)
# ... call the rate-limited HTTP endpoint
end
endperform_later stages the job; the tick admits it when its gates pass.
With multiple gates the actual admit_count per tick comes out as
min(allowed) across all of them.
Choosing the partition scope
partition_by is the most consequential decision in a policy and the
only required field. It tells the gem what counts as one logical
partition — what scope each gate enforces against, and what the
in-tick fairness reorder operates over.
A policy with partition_by and no gates is also valid: the
pipeline passes the full budget through, and the Tick caps it via
admission_batch_size (or tick_admission_budget if set). Useful
for "balance N tenants evenly" without rate-limiting any of them.
If you need genuinely different scopes per gate (throttle by endpoint AND concurrency by account, each enforced at its own scope), split into two policies and chain them: the staging policy admits, its worker enqueues into the second.
Gates
Gates run in declared order; each narrows the survivor count. Every
option that takes a value can alternatively take a lambda receiving
the ctx hash, so parameters can depend on per-job data.
A policy may declare each gate type at most once — two gates of the
same type would share a gate_state key and corrupt each other's
persisted state, so the policy raises InvalidPolicy at definition
time. For multi-window rate limiting (e.g. 10/min and 600/hour), use
separate policies.
:throttle — token-bucket rate limit per partition
Refills rate tokens every per seconds, capped at rate (no
separate burst). Admits jobs while tokens are available; leaves the
rest pending for the next tick. State is persisted in
partitions.gate_state.throttle.
gate :throttle,
rate: ->(ctx) { ctx[:rate_limit] },
per: 1.minuteBoth rate and per accept a lambda receiving the ctx, so the rate
limit and its window can depend on per-job data (e.g. a per-tenant plan
that sets both). A per that resolves to <= 0 raises.
Throttle does not release tokens on completion — tokens refill only with elapsed time.
rate may be fractional (e.g. 2.5): the bucket keeps the fractional
part so the long-run rate is exact rather than truncated. A sub-unit
rate works too — the bucket holds at least one whole token, so e.g.
rate: 1, per: 2.seconds admits one job every two seconds. A rate
of 0 (or nil) denies and backs the partition off for one per
window. Prefer expressing low rates via a longer per.
:concurrency — in-flight cap per partition
Caps the number of admitted-but-not-yet-completed jobs per partition.
Counts rows in dispatch_policy_inflight_jobs keyed by the policy's
canonical partition. Decremented by InflightTracker.track's
around_perform; reaped by a periodic sweeper if a worker crashes.
gate :concurrency,
max: ->(ctx) { ctx[:max_per_account] || 5 }When the cap is full, the gate returns retry_after = full_backoff
(default 1s) so the partition skips the next ticks instead of
hammering count(*) every iteration.
:adaptive_concurrency — per-partition cap that self-tunes
Like :concurrency but the cap (current_max) shrinks when the
adapter queue backs up and grows when workers drain it quickly.
AIMD loop on a per-partition stats row in
dispatch_policy_adaptive_concurrency_stats.
gate :adaptive_concurrency,
initial_max: 3,
target_lag_ms: 1000, # acceptable queue wait before backoff
min: 1 # floor; a partition can't lock out-
Feedback signal:
admitted_at → perform_start(queue wait in the real adapter). Pure saturation signal — slow performs in the downstream service don't punish admissions if workers still drain the queue quickly. -
Growth:
current_max += 1per fast success. -
Slow shrink:
current_max *= 0.95when EWMA lag > target. -
Failure shrink:
current_max *= 0.5whenperformraises. -
Safety valve: when
in_flight == 0the gate floorsremainingatinitial_maxso a partition that AIMD shrunk tominduring a past burst can re-grow when it idles.
Choosing target_lag_ms
It's the knob that trades latency for throughput. Rough guide:
- Too low (10–50 ms): the gate reacts to every tiny bump in queue wait and shrinks aggressively. Workers idle while jobs sit pending — overshoot.
- Too high (30 s+): the gate barely pushes back; throughput is near-max but new admissions wait seconds before a worker picks them up.
-
Reasonable starting point:
≈ worker_threads × avg_perform_ms. E.g. 5 workers × 200 ms perform = 1000 ms means "queue depth up to ~1 s is fine".
Fairness within a tick
When several partitions compete for admission inside the same tick, the gem reorders them by least-recently-active first so a hot partition with thousands of pending jobs cannot starve a cold one that just woke up.
The mechanism has two knobs: an EWMA half-life (controls how the order is decided) and an optional global tick cap (controls how much each partition is allowed in one tick).
fairness half_life:
Each partition keeps decayed_admits and decayed_admits_at,
updated atomically inside the admit transaction:
decayed_admits := decayed_admits * exp(-Δt / τ) + admitted
where τ = half_life / ln(2)
After half_life seconds without admitting, the value halves. The
Tick sorts the claimed batch by current decayed_admits ASC, so the
under-admitted go first.
| Value | Behaviour |
|---|---|
| 5–10 s | Reacts to brief pauses. Bursty workloads where short stalls deserve a head start. |
| 60 s (default) | Stable steady-state. Hot partitions stay "hot" through normal latency variation. |
| 5–15 min | Long memory. Burst on partition A penalises A for many minutes. |
Set c.fairness_half_life_seconds = nil to disable the reorder
entirely — partitions are processed in claim_partitions order
(last-checked-first).
tick_admission_budget
Without this, each partition admits up to admission_batch_size.
With it set, the per-partition ceiling becomes fair_share = ceil(cap / claimed_partitions). Pass-1 walks the (decay-sorted) partitions
giving each up to fair_share; pass-2 redistributes any leftover to
those that filled their share.
DispatchPolicy.configure do |c|
c.fairness_half_life_seconds = 60
c.tick_admission_budget = nil # default — no global cap
end
# Per-policy override:
dispatch_policy :endpoints do
partition_by ->(c) { c[:endpoint_id] }
fairness half_life: 30.seconds
tick_admission_budget 200
gate :throttle, rate: 100, per: 60
endWhen the cap is hit before all partitions admit, the rest are denied
with reason tick_cap_exhausted. They were still observed
(last_checked_at bumped), so they're at the front of the next
tick's order.
Anti-stagnation
The decay-based reorder only applies to partitions already claimed.
Selection (Repository.claim_partitions) still orders by
last_checked_at NULLS FIRST, id. Every active partition with
pending jobs is visited in at most ⌈N / partition_batch_size⌉ ticks
regardless of how hot or cold it is.
Mixing :adaptive_concurrency with fairness
Adaptive and fairness operate at different layers and compose without sharing state:
-
Fairness writes
partitions.decayed_admitsinside the per-partition admit TX. -
Adaptive writes
dispatch_policy_adaptive_concurrency_statsfrom the worker'saround_performviarecord_observation.
Different tables, different locks. Each tick the actual admit_count
becomes min(fair_share, current_max - in_flight) (with the
adaptive safety valve when in_flight == 0). Fairness picks order +
budget per tick; adaptive shapes how aggressively each partition
consumes its share.
dispatch_policy :tenants do
partition_by ->(c) { c[:tenant] }
gate :adaptive_concurrency,
initial_max: 5,
target_lag_ms: 1000,
min: 1
fairness half_life: 30.seconds
tick_admission_budget 60
endThe dummy AdaptiveDemoJob declares both; the storm form drives it
across many tenants with a triangular weight distribution so you can
watch the EWMA reorder hot tenants AND the AIMD shrink their cap.
Integration test: test/integration/adaptive_with_fairness_test.rb.
Sharding a policy across worker pools
Shards partition the gem horizontally: each tick worker sees only
the partitions on its own shard, so multiple workers can admit in
parallel for the same policy. Declare a shard_by:
dispatch_policy :events do
context ->(args) { { account_id: args.first[:account_id] } }
partition_by ->(c) { "acct:#{c[:account_id]}" }
shard_by ->(c) { "events-shard-#{c[:account_id].hash.abs % 4}" }
gate :concurrency, max: 50
endRun one DispatchTickLoopJob per shard:
4.times { |i| DispatchTickLoopJob.perform_later("events", "events-shard-#{i}") }The generated DispatchTickLoopJob template uses
queue_as { arguments[1] } so each tick is enqueued on the same
queue it monitors. Workers listening on events-shard-* queues run
both the tick loops and the admitted jobs from one pool per shard.
The gem's automatic context enrichment puts :queue_name into the
ctx hash so shard_by can use it directly without your context
proc having to know about it.
shard_by must be ≥ as coarse as the most restrictive throttle's
scope. If not, the bucket duplicates across shards and the
effective rate becomes rate × N_shards.
Atomic admission
Forwarder.dispatch runs inside the per-partition admission
transaction. The adapter (good_job, solid_queue) uses
ActiveRecord::Base.connection, so its INSERT INTO good_jobs
joins the same TX as the DELETE FROM staged_jobs and the INSERT INTO inflight_jobs. Any exception (deserialize, adapter error,
network) rolls everything back atomically — no window where staged
is gone but the adapter never received the job.
The trade-off: the gem requires a PG-backed adapter for at-least-once. The railtie warns at boot if the adapter doesn't look PG-shared (Sidekiq, Resque, async, …) but doesn't hard-fail — a custom PG-backed adapter we don't recognise can still work.
For Rails multi-DB (e.g. solid_queue on a separate :queue role):
DispatchPolicy.configure do |c|
c.database_role = :queue
endWhen set, every DB access the gem makes runs inside
connected_to(role:) — staging on perform_later, the admission TX,
inflight tracking and its heartbeat thread, sweeps, and the admin UI
(an around_action routes each dashboard request, so its reads and
operator actions hit the same DB the tick writes). Staging tables and
the adapter's table must live in the same DB for atomicity to hold.
Job identity across staging and adapter
Tick.admit_partition regenerates the ActiveJob job_id for every
claimed row immediately before pre-inserting inflight_jobs and
handing the job to the adapter. So a job has two identities through
its lifecycle:
-
Pre-admission —
staged_jobs.id(the staged-side identity) andstaged_jobs.job_data->>'job_id'(the UUIDperform_laterreturned to the caller). -
Post-admission —
inflight_jobs.active_job_idand the adapter's row id (good_jobs.id/solid_queue_jobs.id), both equal to the newly generated UUID. This is also thejob_idthe worker observes during perform.
The two UUIDs are intentionally different. Adapters that use
active_job_id as their PK (good_job, solid_queue) would
otherwise collide on the adapter row when a previous admission of
the same staged job left a residual row behind — most commonly a
retry-restage whose original adapter row had not been finalized yet.
The mapping is logged at debug level on every admission:
[dispatch_policy] admit staged_id=… policy=… partition=… active_job_id: <old> -> <new>
If you correlate jobs across the staging boundary from outside Rails,
use staged_jobs.id as the stable handle pre-admission and the
adapter row id (= inflight_jobs.active_job_id) post-admission.
Running the tick
DispatchPolicy::TickLoop.run(policy_name:, shard:, stop_when:) is
the entry point. It claims partitions under FOR UPDATE SKIP LOCKED, evaluates gates, atomically admits, and updates partition
state. The install generator scaffolds a DispatchTickLoopJob you
schedule like any other ActiveJob:
DispatchTickLoopJob.perform_later # all policies
DispatchTickLoopJob.perform_later("endpoints") # one policy
DispatchTickLoopJob.perform_later("endpoints", "shard-2")Each job uses good_job_control_concurrency_with (or solid_queue's
limits_concurrency) so only one tick is active per
(policy, shard) combination at a time. The job re-enqueues itself
with a 1-second tail wait, so the loop survives normal restarts.
Admin UI
Mount the engine and visit /dispatch_policy:
-
Dashboard — totals, throughput windows, round-trip stats,
capacity gauges (admit rate vs adapter ceiling, avg tick vs
tick_max_duration), pending trend with up/down arrow, auto-hints ("avg tick at 88% of tick_max_duration — shard or lower admission_batch_size"). -
Policies — per-policy throughput, denial reasons breakdown,
top partitions by lifetime/pending, pause/resume/drain. Pause is a
policy-level flag (stored in
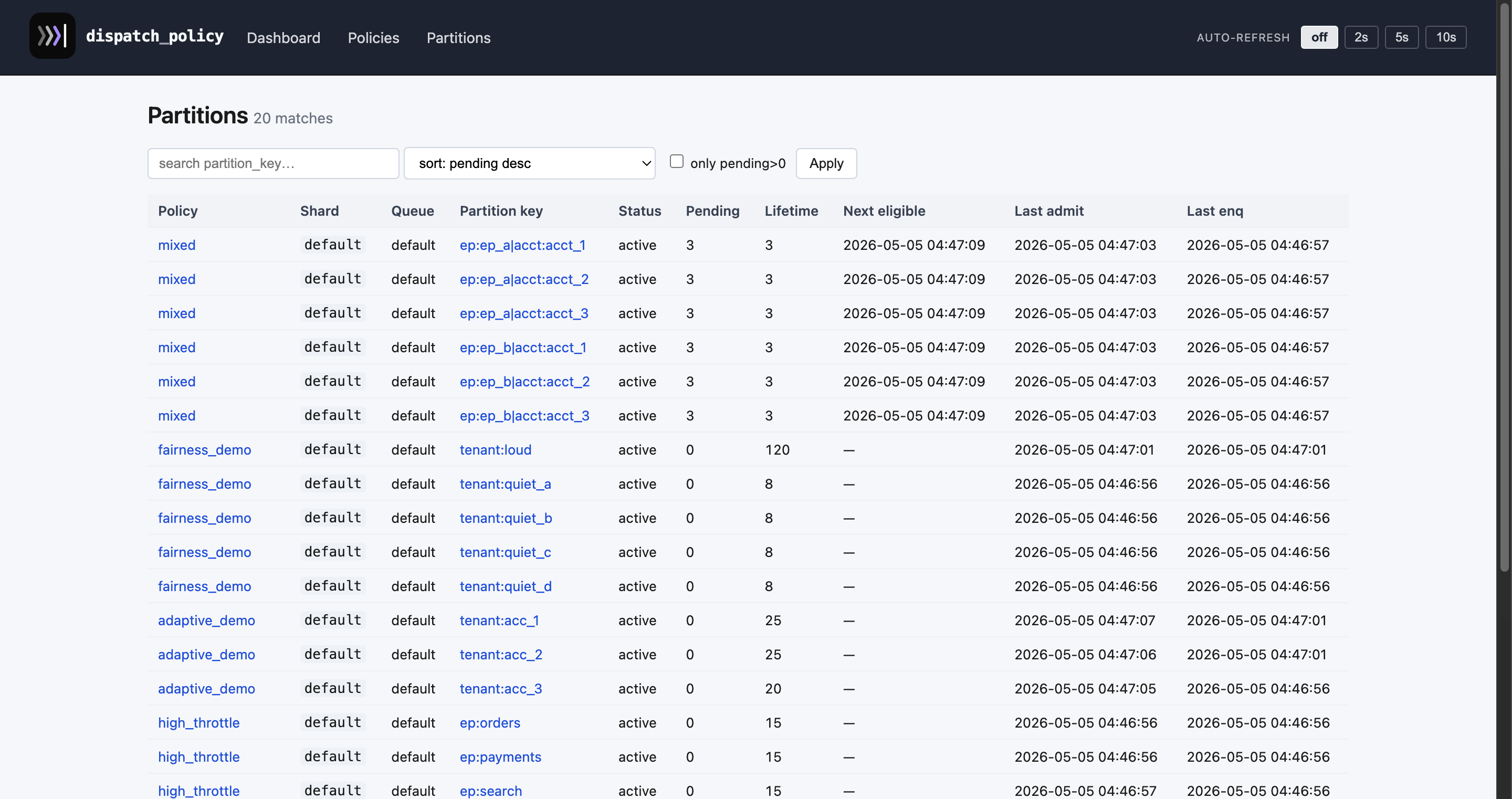
dispatch_policy_policy_settings) the tick honors, so it also holds partitions that first appear after the pause; resume clears it. - Partitions — searchable list, detail view with gate state, decayed_admits + admits/min estimate, recent staged jobs, force-admit, drain.
The UI auto-refreshes via Turbo morph + a controllable picker (off / 2s / 5s / 10s) stored in sessionStorage; preserves scroll position; and skips a refresh while a previous Turbo visit is in flight so a slow page doesn't stack visits.
CSRF and forgery protection use the host app's settings. The UI
ships unauthenticated; wrap the mount with a constraint or
before_action for auth in production.
Configuration
# config/initializers/dispatch_policy.rb
DispatchPolicy.configure do |c|
c.tick_max_duration = 25 # seconds the tick job stays admitting
c.partition_batch_size = 50 # partitions claimed per tick iteration
c.admission_batch_size = 100 # max jobs admitted per partition per iteration
c.idle_pause = 0.5 # seconds slept when a tick admits nothing
c.partition_inactive_after = 86_400 # GC partitions idle this long
c.inflight_stale_after = 300 # GC inflight rows whose worker stopped heartbeating
c.inflight_queued_stale_after = 3_600 # GC inflight rows admitted but never started (queued)
c.inflight_heartbeat_interval = 30 # how often the worker bumps heartbeat_at; 0 disables the thread
c.sweep_every_ticks = 50 # sweeper cadence (in tick iterations); <= 0 never sweeps
c.metrics_retention = 86_400 # tick_samples kept this long
c.fairness_half_life_seconds = 60 # EWMA half-life for in-tick reorder; nil disables
c.tick_admission_budget = nil # global cap on admissions per tick; nil = none
c.adapter_throughput_target = nil # jobs/sec; UI shows admit rate as % of this
c.database_role = nil # AR role ALL gem DB access runs against (multi-DB)
endYou can override admission_batch_size, fairness_half_life_seconds,
and tick_admission_budget per policy via the DSL.
partitions.context is refreshed on every enqueue
When you call perform_later, the gem evaluates your context proc
and upserts the partition row with the resulting hash:
INSERT INTO dispatch_policy_partitions (..., context, context_updated_at, ...) VALUES (...)
ON CONFLICT (policy_name, partition_key) DO UPDATE
SET context = EXCLUDED.context,
context_updated_at = EXCLUDED.context_updated_at,
pending_count = dispatch_policy_partitions.pending_count + 1,
...Gates evaluate against partition.context, not the per-job
snapshot in staged_jobs.context. So if a tenant bumps their
dispatch_concurrency from 5 to 20 and a new job arrives, the next
admission uses the new value — no need to drain the partition
first. If a partition has no new traffic, the context stays at the
value seen by the last enqueue.
Retry strategies
By default a retry produced by retry_on re-enters the policy and
is staged again, so throttle/concurrency apply equally to first
attempts and retries. Use retry_strategy :bypass if you want
retries to skip the gem and go straight to the adapter:
dispatch_policy :foo do
partition_by ->(_c) { "k" }
gate :throttle, rate: 5, per: 60
retry_strategy :bypass
endCompatibility
- Rails 7.1+ (developed against 8.1).
- PostgreSQL 12+ (uses
FOR UPDATE SKIP LOCKED,JSONB,ON CONFLICT). -
good_job≥ 4.0 orsolid_queue≥ 1.0. - Sidekiq / Resque are NOT supported — the at-least-once guarantee needs the adapter to share Postgres with the gem.
Testing
bundle exec rake test # 124 runs / 284 assertions
bundle exec rake bench # manual benchmark suite (creates dispatch_policy_bench DB)
bundle exec rake bench:real # end-to-end against good_job on the dummy DB
bundle exec rake bench:limits # stretches every path to its breaking pointIntegration tests skip when no Postgres is reachable (default DB
dispatch_policy_test; override via DB_NAME, DB_HOST,
DB_USER, DB_PASS).
Releasing
Cutting a new version is driven by bin/release. Steps:
-
Bump
DispatchPolicy::VERSIONinlib/dispatch_policy/version.rb. -
Add a
## <VERSION>section inCHANGELOG.mddescribing the release. The script extracts that section verbatim as the GitHub release notes, so anything missing here will be missing on GitHub. -
Commit both on
masterand push soorigin/mastermatches local. -
Run the script from the repo root:
bin/release
The script:
- Refuses to run unless you are on
master, the working tree is clean, the local branch matchesorigin/master, and the tagv<VERSION>does not yet exist. - Asks for a
yconfirmation before doing anything. - Hands off to
bundle exec rake release(builds the gem, creates thev<VERSION>tag, pushes the tag to GitHub, pushes the gem to RubyGems.org). - Creates a GitHub release for
v<VERSION>using the matching CHANGELOG section as the body. Requires theghCLI; if it is missing, the gem ships but you'll need to create the GitHub release manually withgh release create v<VERSION> --notes-file CHANGELOG.md.
Prerequisites: a configured ~/.gem/credentials for RubyGems push
and gh auth login for the GitHub release.
License
MIT.